
Three months ago I wrote about why I was building Codex: years of daily Komga use, a few stubborn limitations, and two previous attempts at building my own digital library server that fizzled out somewhere in the middle. The post was speculative in places. The core was working, but a lot of “what’s next” was still on a list.
This is the follow-up. Three months of daily use later, here’s what changed, what shipped, and what I learned.
I use it every day, and that changed everything
The single most important thing that happened to Codex in the last three months is that it became my actual library. Not “the project I work on” but “the thing I open every day to read manga.” Komga is retired on my server. The migration was uneventful, which is the highest compliment I can pay it.
This shift sounds small, but it changes the development loop in concrete ways. Bugs that an automated test suite would never catch surface within a week of regular use: a thumbnail that loads slowly on a 90-volume series, a reader setting that doesn’t persist after a long break, a metadata refresh job that runs slightly too aggressively. Every reading session is an integration test.
It also reorders the “next features” list naturally. The thing I want most this week is the thing I missed during last weekend’s reading. That has been a much better prioritization signal than any roadmap I wrote up front.
The headline feature: Release Tracking
The biggest new subsystem is Release Tracking.
The problem it solves is one I lived with for years: I follow ongoing series, new volumes drop, and I find out weeks late, by accident, when I happen to scroll through MangaUpdates or stumble onto a torrent on Nyaa. Komga doesn’t help here, and neither did the first version of Codex.
Codex now polls upstream sources on a per-source cron schedule, matches incoming releases against tracked series using external IDs and normalized title aliases, and surfaces them in two places: a cross-series inbox with facets, bulk actions, and per-row operations, and a per-series releases panel that filters between New and All.
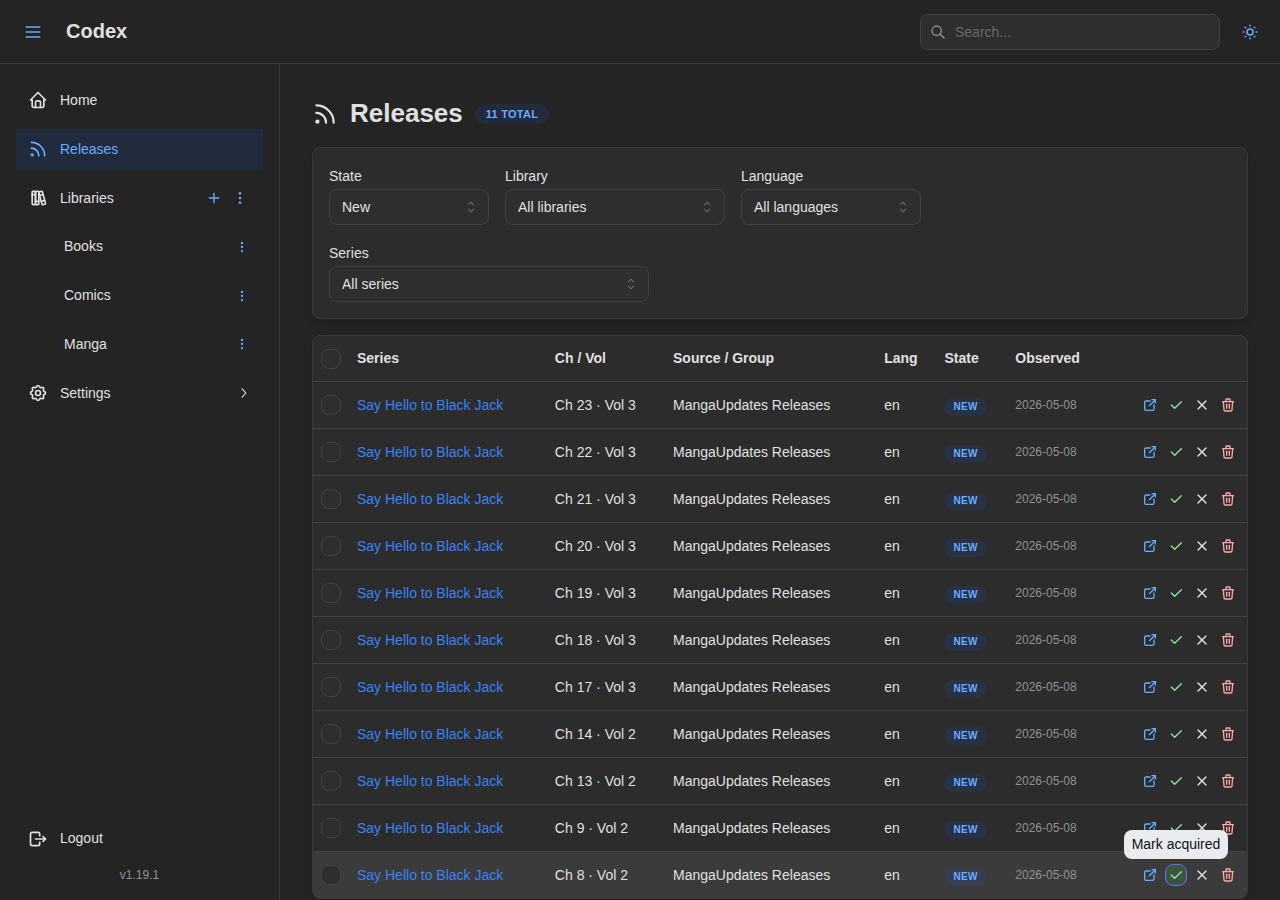
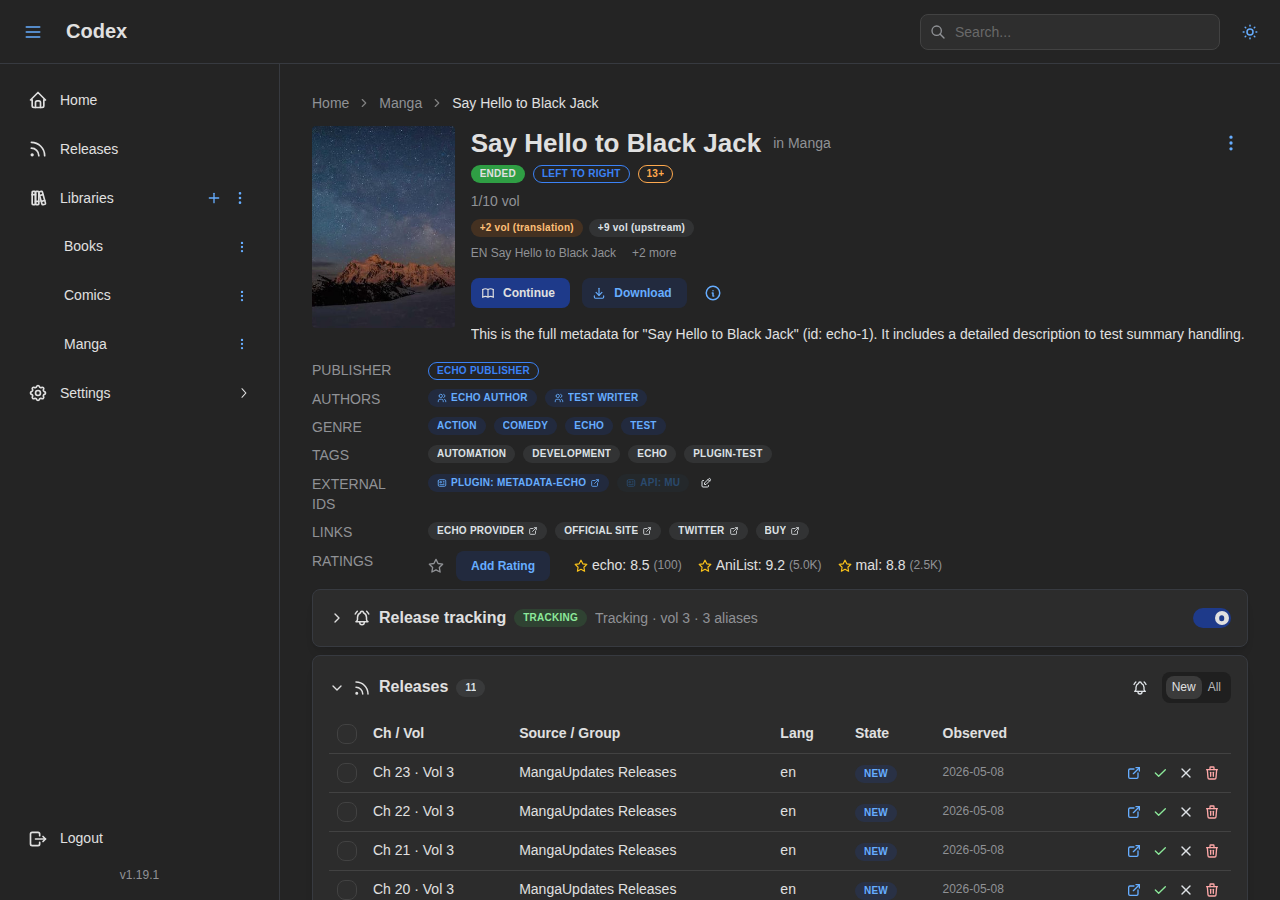
The whole thing rides on the existing plugin protocol. Release sources are just plugins with a release_source capability, and they call back through a reverse-RPC at startup to register their sources. Today there are two: release-mangaupdates (RSS-based feed of titles) and release-nyaa (uploader-feed, with direct fetch URLs). Adding another, MyAnimeList for example, is a few hundred lines of TypeScript against the SDK.
A few things I’m happy about in this design:
- Already-owned releases are auto-ignored when a series is first seeded, so the inbox doesn’t drown in noise on day one.
- Each release row carries an optional direct-fetch URL with a typed kind (e.g.
torrent_file), so the UI can offer the right action without baking source-specific logic into the core. - Polling is per-host backoff aware. MangaUpdates and Nyaa each have their own rate budgets, and the scheduler respects them without knowing source-specific rules.
The plugin system grew up
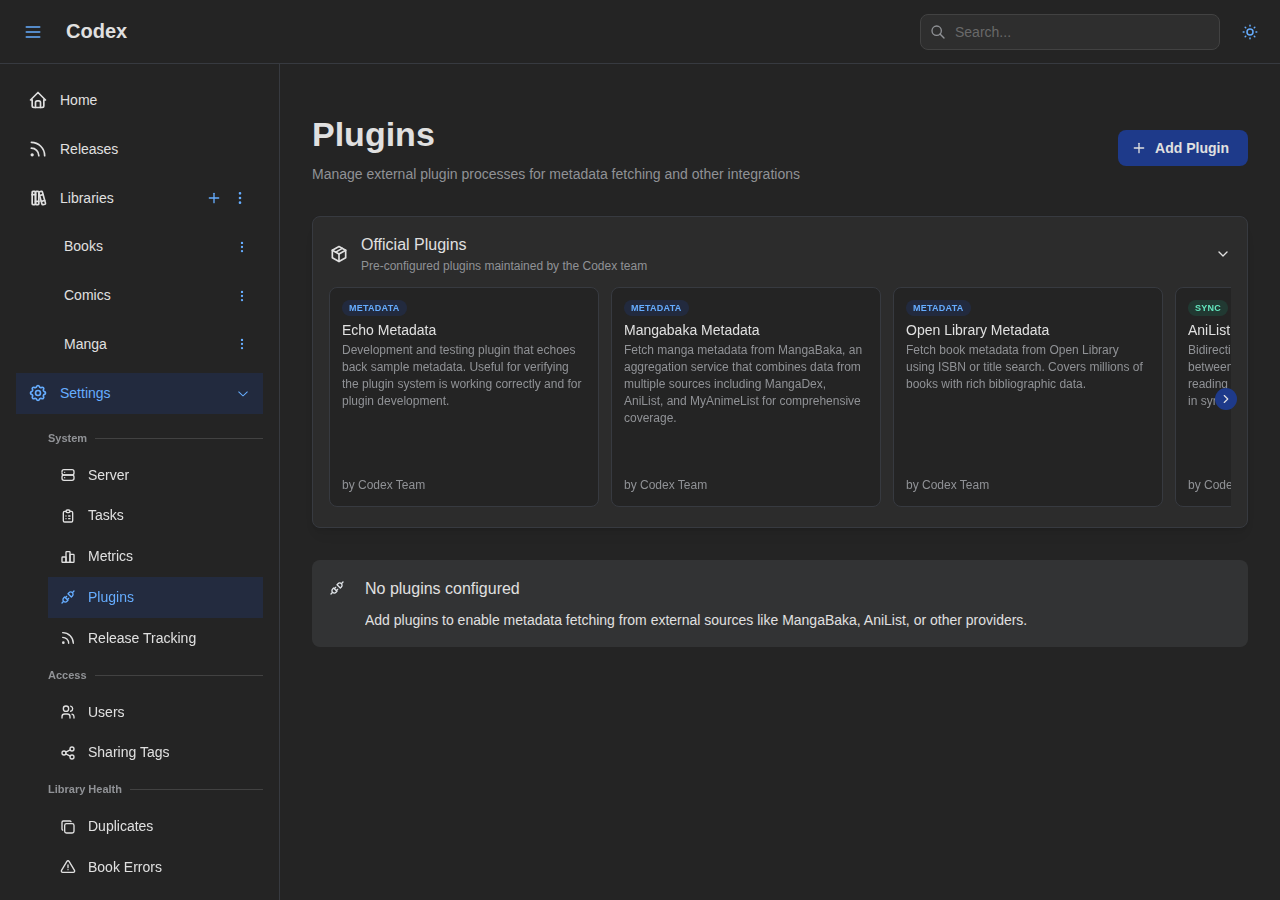
The first post described the plugin system as JSON-RPC 2.0 over stdio, modeled loosely on MCP servers. At that point it only did metadata. Three months later it does a lot more.
The protocol got two important upgrades:
- Capability-gated reverse-RPC, where plugins can call back into Codex for operations they’re authorized to do (like registering release sources), instead of only responding to requests.
- Multiple capabilities per plugin process, so a single plugin binary can expose metadata, release sources, recommendations, and sync without spawning four processes.
The plugin types now include:
- Metadata (Open Library, MangaBaka, and Echo for SDK testing)
- Release Source (MangaUpdates, Nyaa)
- Recommendations (AniList, per-user)
- Sync (AniList bidirectional progress sync)
The recommendations plugin was the first one that made me feel like the system was paying for itself. AniList already knows what I read; surfacing personalized picks on the home page was a few hundred lines of TypeScript and zero Rust changes.
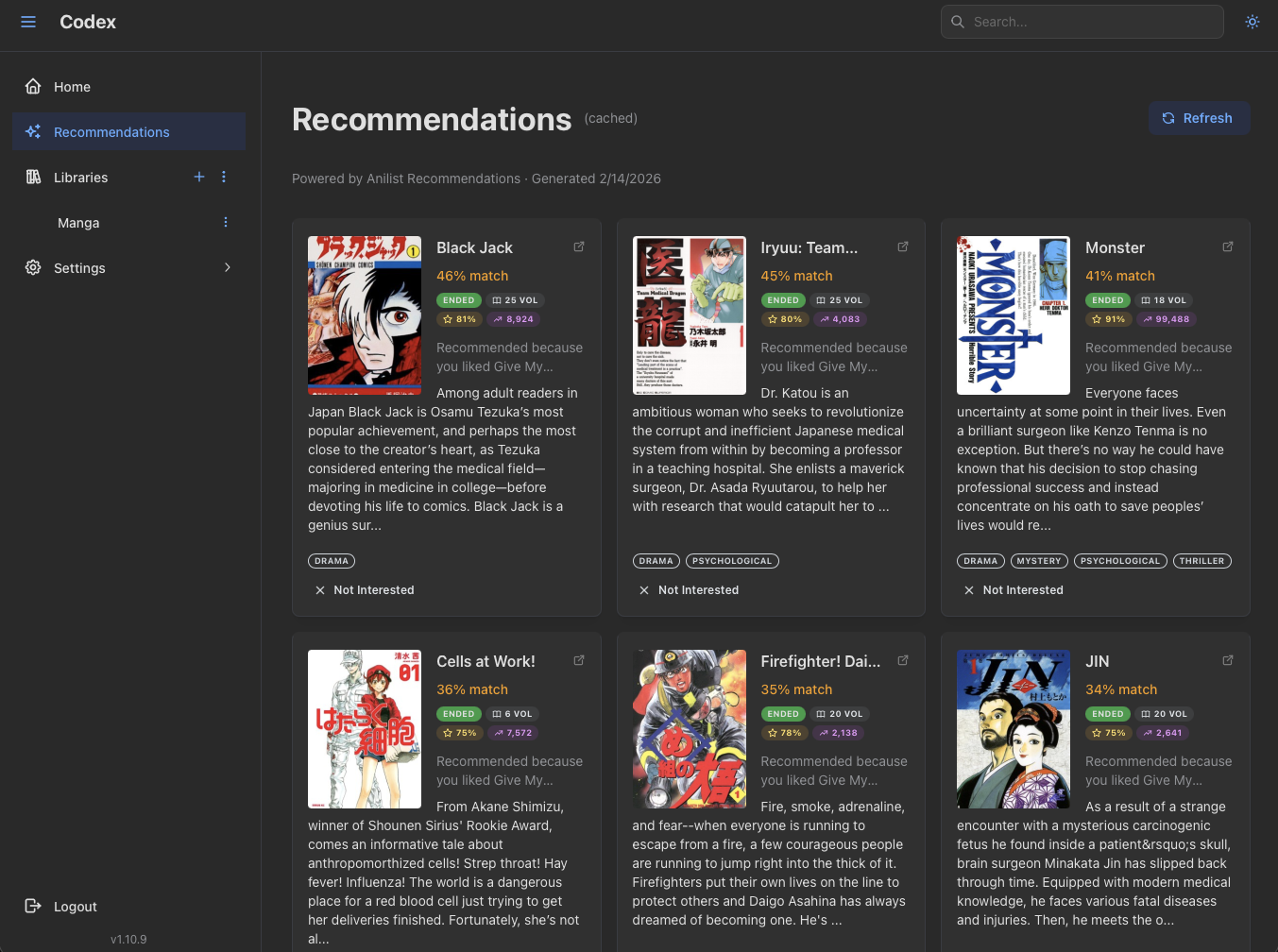
The bet I made in February (Rust core, polyglot plugins) has paid off concretely. None of these new plugin types required Rust changes to the plugin runtime itself. Release tracking added one new capability and a reverse-RPC method; the rest was new TypeScript plugins against the SDK.
The unglamorous polish
A bunch of smaller things shipped that, individually, aren’t blog-worthy, but collectively make a real difference.
Library Jobs. The single per-library “metadata refresh config” was replaced with N typed jobs. Each library can now run multiple metadata-refresh jobs against different providers, each with its own cron, field allowlist, and recency guard (skip series whose external IDs were synced in the last N hours). The config is type-discriminated on type, so adding new job kinds later doesn’t require a schema migration.
Exports. Users can export their catalog to JSON, CSV, or Markdown, with configurable field selection and built-in LLM-friendly presets. Generation runs as a background task, expirations are handled by a scheduled cleanup job, and download filenames include the selected library names so artifacts are self-describing.
Active-tasks badge. The little badge in the header now shows live progress, target titles (which series is being scanned right now), and elapsed time. Nine more task handlers learned to emit progress events so the badge has something real to show.
OIDC. This was on the “what’s next” list in the first post. It shipped. Multiple simultaneous OIDC providers, group-to-role mapping, configurable claims, and optional auto-creation of users on first login. Keycloak and Authentik both work out of the box.
Sharing tags. Per-user content access control, useful for family setups where the kids’ tablet shouldn’t see everything in the library. Series carry tags, users carry tags, and users only see series whose tags overlap with theirs (or have no tags at all).
KOReader sync. A small compatibility layer that lets KOReader devices push and pull reading progress against Codex, alongside the existing Komga-compatible API. Same idea: meet existing readers where they are.
Custom metadata. One of the gripes in the first post was the lack of user-defined metadata fields. That landed: series and books both support custom fields with admin-defined templates, and they participate in the standard field-lock and export systems.
What I learned
A few things I didn’t expect.
Daily use is a better roadmap than a roadmap. Most of what shipped in the last three months wasn’t on the February list. Release tracking wasn’t. Library jobs as a typed-config thing wasn’t. The active-tasks badge UX wasn’t. They came from “I wish this worked better” while reading, not from sitting down to plan.
The plugin protocol was the right load-bearing decision. Every external integration that landed in this period rode the same transport. Release sources, recommendations, sync, all sit on top of one well-tested protocol. The friction of “I need to write Rust to add an integration” never came up, and the SDK kept getting easier.
Polish is quietly more work than features. Library Jobs as a concept took a couple of days. Replacing the old single-config UI with the typed-job UI, plus migrations, plus dry-run, plus the recency guard, plus the per-library job list with proper progress reporting, plus the test scaffolding, took weeks. The feature was 20%; the operational surface was 80%.
Self-hosters have opinions about defaults, including me. A surprising number of decisions that seemed clear-cut at design time turned out to be configurable settings. Not because someone asked, but because I caught myself wanting different defaults for different libraries.
What’s next
The roadmap has changed, but not by much:
- More metadata providers
- More release sources
- An AI-powered recommendation plugin
- An iOS app to replace Komic and surface the Codex features the Komga API can’t reach
If you want to try it, the source is on GitHub, the docs are live, and the Docker image is publicly available. The first post is still the why behind all this.