
積ん読 (tsundoku) is the Japanese word for the habit of acquiring books and letting them pile up unread. It’s an affectionate kind of self-deprecation, and it’s an uncomfortably accurate description of how I read manga. There’s always a new series I’ve heard is good, a sequel that just got a fresh volume, a thing someone mentioned in passing that I meant to look into. The pile only grows.
A few months ago I wrote about Codex, the Rust digital library server I built to manage the comics, manga, and ebooks I already own. Codex is great at the “own” part. It scans my files, fetches metadata, tracks what I have. But it has nothing to say about the part that actually feeds the collection: discovery. What’s new? What got a new volume since I last looked? What have I been meaning to start but never got around to?
That gap was still a manual chore. So I built Tsundoku to close it.
What Tsundoku Is (and Deliberately Isn’t)
Tsundoku is a standalone manga discovery service. It polls one or more release sources (Nyaa.si is the only source in v1), resolves each discovered release to a canonical series via a metadata provider (MangaBaka in v1), and maintains a local, browsable catalog of series I have not yet imported into Codex.
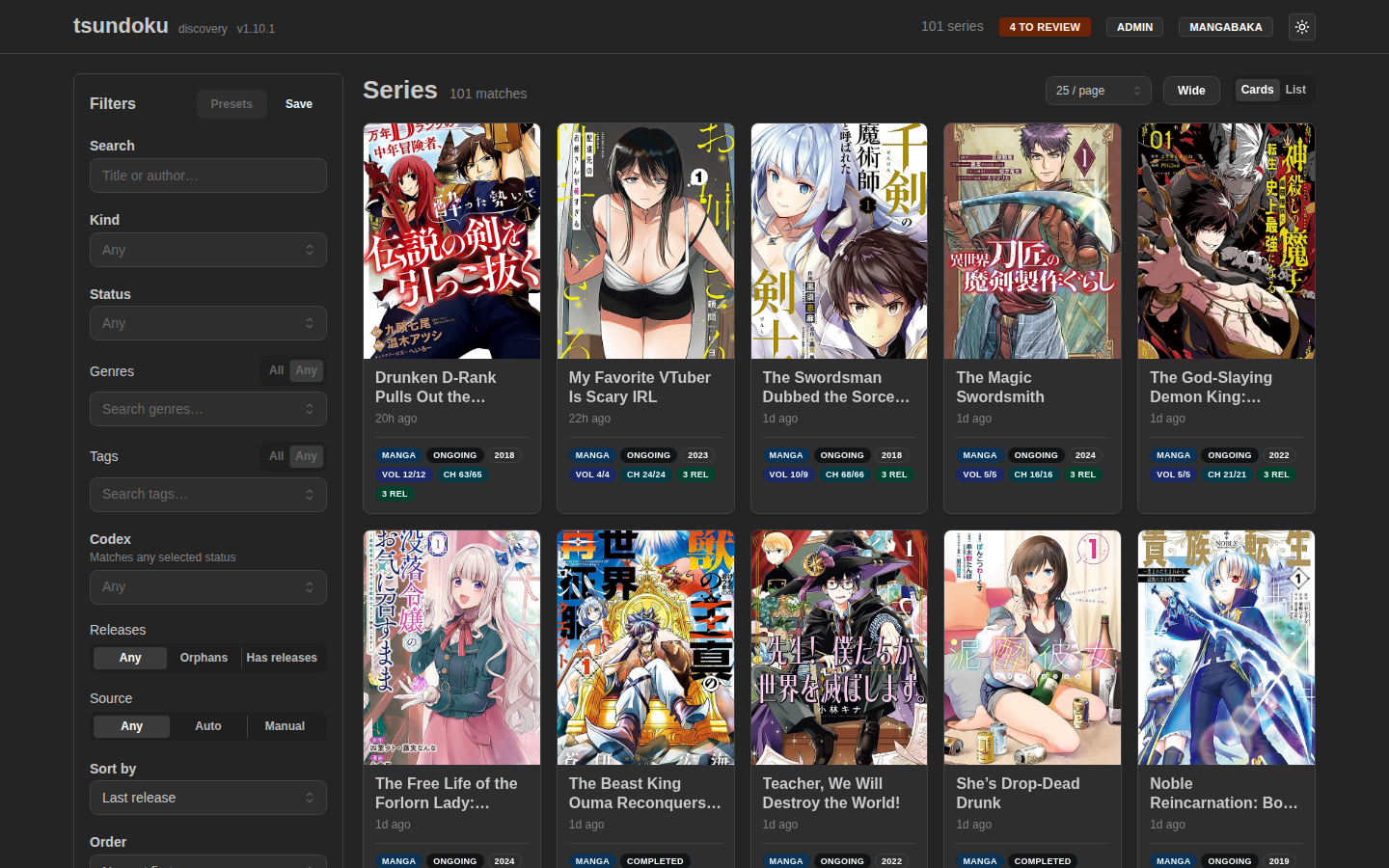
The Tsundoku feed: a browsable, filterable catalog of discovered series, each resolved from raw release titles to real metadata with covers.
What makes it useful is mostly what it refuses to do:
- It does not track individual release postings for series I already own. That’s Codex’s job (via its
release-nyaaplugin). Tsundoku still flags series I own but am behind on (via the Codex overlay, more on that later); it just doesn’t try to be the per-release feed for things already in my library. - It does not download or post-process torrents. It is not a Sonarr-for-manga.
- It does not track download progress. It has no opinion about your seedbox’s queue.
- It does not reach into Codex’s database. Any integration happens over Codex’s HTTP API, read-only.
- It is strictly single-user, single-host, one SQLite file. No multi-tenancy, no clustering, no Postgres.
It ships as one Rust binary (axum + sea-orm + SQLite) with the React SPA embedded directly in the binary via rust-embed, deployed as a single container with a single volume. If that operational shape sounds familiar, it’s the same one I used for Codex and HiveLabs. I’ve converged on it because it’s boring in the best way: one artifact, one port, one thing to back up.
The Actual Hard Problem
Here’s the thing nobody tells you about manga discovery: the source data is garbage.
A release on a tracker looks like this:
[GroupName] Jojo's Bizarre Adventure - Part 7 - Steel Ball Run v01-v24 (2020) (Digital) (XRA)
A human reads that and instantly knows it’s JoJo’s Bizarre Adventure: Part 7–Steel Ball Run, volumes 1 through 24. A computer sees a noisy string with a scanlation group, a part number, a volume range, a year, and three sets of parentheses that mean nothing. Multiply that by hundreds of releases a day, across dozens of naming conventions, half of them with typos, and the core challenge of the whole project becomes obvious:
How do you reliably turn a release title into “this is series X in my canonical catalog”?
Everything else in Tsundoku, the catalog, the filtering, the Codex overlay, the send-to-client button, depends on that one mapping being trustworthy. Get it wrong and you’ve built a database of nonsense.
The One Architectural Decision That Mattered
Before any of that, I had to decide how a “series” is even identified. This is where most metadata systems quietly paint themselves into a corner: they key everything off whatever provider they happened to start with. Your series is its MangaDex ID, or its AniList ID, and the day you want to swap providers you’re rewriting your schema.
Tsundoku’s single most important design choice is a surrogate series ID plus an external-IDs mapping table:
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#e8eef7', 'primaryTextColor': '#1a1a2e', 'primaryBorderColor': '#4a6fa5', 'lineColor': '#4a6fa5', 'textColor': '#1a1a2e', 'edgeLabelBackground': '#f8f9fc', 'clusterBkg': '#eef2f9', 'clusterBorder': '#4a6fa5' }}}%%
flowchart LR
subgraph S["series"]
direction TB
ID["id (surrogate, AUTOINCREMENT)<br/>titles, kind, status, year,<br/>cover, rating, owned…"]
end
subgraph X["series_external_ids"]
direction TB
MB["mangabaka → 12345"]
MU["mangaupdates → 67890"]
AL["anilist → 4242"]
MAL["mal → 1111"]
end
S -->|"1 series ↔ N provider IDs<br/>UNIQUE(series_id, provider)"| X
style ID fill:#e8eef7,stroke:#4a6fa5,color:#1a1a2e
style MB fill:#e6f4ea,stroke:#28a745,color:#1a1a2e
The series row is provider-agnostic. It has its own integer primary key that means nothing outside Tsundoku. Every provider ID it’s known by lives in series_external_ids, keyed by (provider, external_id) with a UNIQUE(series_id, provider) constraint: one series per provider ID, and one provider ID per series, in both directions.
The payoff is that adding or swapping a metadata provider never requires a series-schema change. The whole backend is built around this: there’s a MetadataProvider trait, MangaBaka is just the first implementation, and other providers can stay registered purely to cross-resolve foreign IDs even when they’re not the active one. The same pattern repeats for DiscoverySource (Nyaa is one implementation) and DownloadClient (ruTorrent is one implementation). Three trait-shaped seams, each with exactly one v1 implementation, so the abstraction is paid for but not over-engineered. They’re all in-process traits, not subprocess plugins. Single binary, single author, no JSON-RPC ceremony.
The Resolution Pipeline
With identity settled, the title-to-series problem becomes a pipeline. Tsundoku runs four ordered steps and takes the first match:
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#e8eef7', 'primaryTextColor': '#1a1a2e', 'primaryBorderColor': '#4a6fa5', 'lineColor': '#4a6fa5', 'textColor': '#1a1a2e', 'edgeLabelBackground': '#f8f9fc', 'clusterBkg': '#eef2f9', 'clusterBorder': '#4a6fa5' }}}%%
flowchart TB
R["Discovered release<br/>(title + extracted links)"] --> S1
S1{"1. Known external ID?<br/>links already in<br/>series_external_ids"}
S1 -->|hit| RES["resolved<br/>(no provider call)"]
S1 -->|miss| S2
S2{"2. Foreign-ID lookup<br/>ask provider to resolve<br/>e.g. MangaUpdates → MangaBaka"}
S2 -->|hit| RES2["resolved<br/>+ fan out all known IDs"]
S2 -->|miss| S3
S3{"3. Fuzzy title match<br/>clean title, search provider,<br/>Sørensen–Dice re-rank"}
S3 -->|"≥ threshold"| RES3["resolved"]
S3 -->|"plausible"| RQ["review_pending<br/>(into review queue)"]
S3 -->|"nothing"| UR["unresolved"]
RES3 --> S4{"4. Format-to-kind check<br/>e.g. CBZ on a 'novel'?"}
S4 -->|ok| DONE["stays resolved"]
S4 -->|mismatch| AMB["ambiguous<br/>(keeps link, flags for review)"]
style RES fill:#e6f4ea,stroke:#28a745,color:#1a1a2e
style RES2 fill:#e6f4ea,stroke:#28a745,color:#1a1a2e
style RES3 fill:#e6f4ea,stroke:#28a745,color:#1a1a2e
style DONE fill:#e6f4ea,stroke:#28a745,color:#1a1a2e
style RQ fill:#fdf3e3,stroke:#d4a043,color:#1a1a2e
style AMB fill:#fdf3e3,stroke:#d4a043,color:#1a1a2e
style UR fill:#f8d7da,stroke:#dc3545,color:#1a1a2e
Step 1: Known external ID. Nyaa uploaders often link the series page they’re posting (a MangaUpdates, AniList, MAL, MangaDex, or MangaBaka URL) right in the description. Tsundoku scrapes those links out of the post HTML. If any (provider, foreign_id) is already in series_external_ids, we have an instant hit with zero provider calls. The “Information:” field that Nyaa uses for the uploader’s canonical series pointer gets tried first, ahead of body links, because it’s the most authoritative signal in the post.
Step 2: Foreign-ID lookup. A link we’ve never seen before, say a MangaUpdates ID, gets handed to the active provider’s resolve_by_foreign_id. MangaBaka exposes /v1/source/manga-updates/{id}, so a MangaUpdates link resolves straight to a MangaBaka series. On a hit, we upsert the series and fan every cross-provider ID it knows about into series_external_ids, so the next release that links any of those IDs short-circuits at step 1.
Step 3: Fuzzy title. Only when there are no usable links do we fall back to matching on the title itself. Clean the string (strip format keywords, group tags, punctuation), search the provider, then re-rank the candidates with the Sørensen–Dice coefficient over character bigrams against both the canonical and alternate titles. Above the confidence threshold (0.85 by default) it’s an automatic match. Plausible-but-below (down to 0.55) becomes review_pending with the candidates recorded, rather than a silent wrong guess.
Step 4: Format-to-kind validation. This one runs after a confident match, as a sanity check. Declarative rules map file formats to allowed series kinds. If a release is a CBZ (a comic archive) but it just resolved to something MangaBaka calls a novel, that’s almost certainly wrong, so it gets demoted from resolved to ambiguous. Crucially it keeps the link, so the review UI has the context to let me make the call instead of throwing the work away.
You can watch the pipeline’s behaviour in aggregate on the metrics page. In a typical poll, most releases resolve via known/foreign IDs and never touch the fuzzy matcher at all:
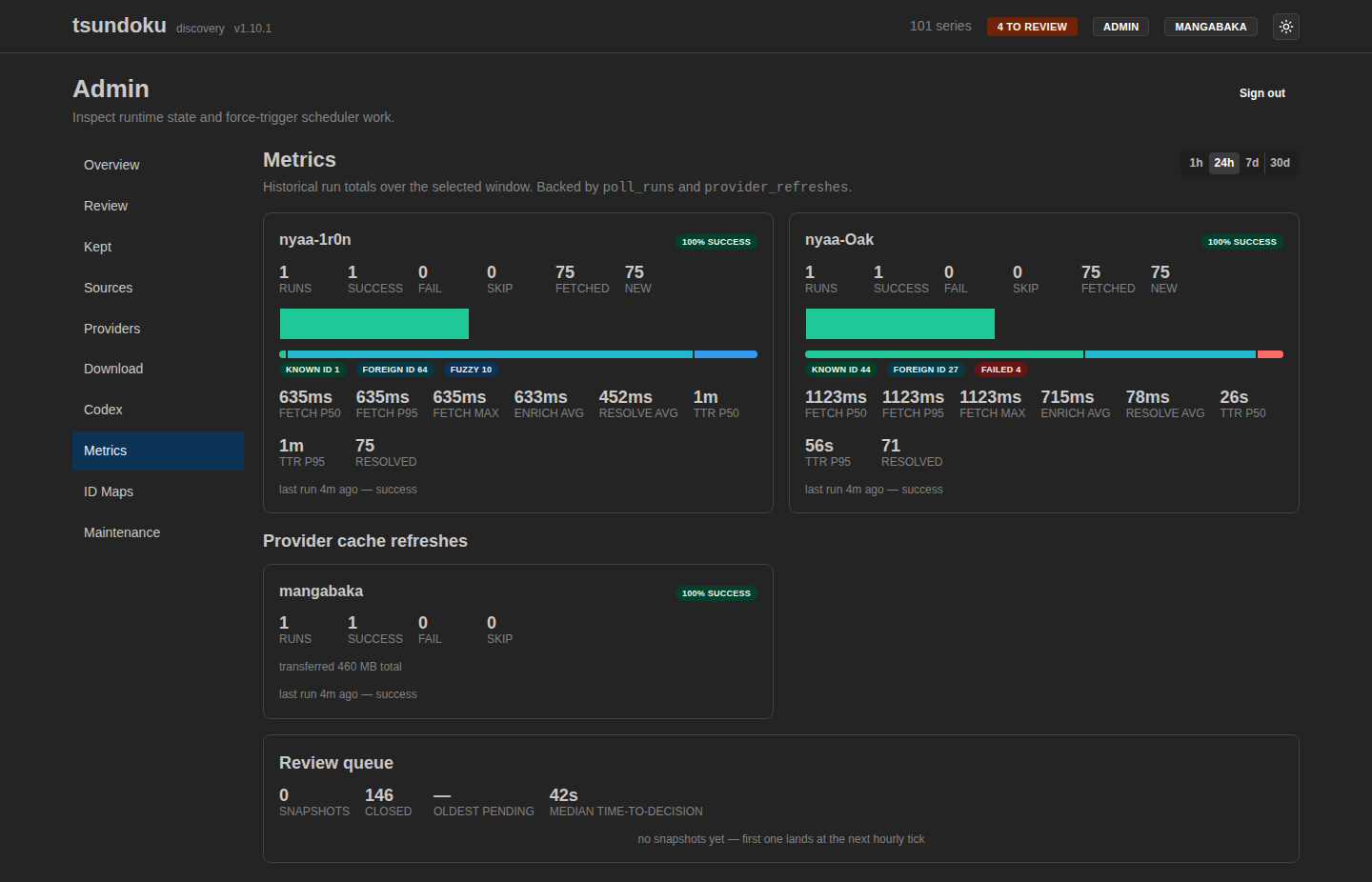
Resolution metrics across two Nyaa sources. On one source’s latest poll, of 75 releases most resolved by foreign-ID lookup (64), a handful fell through to fuzzy title matching (10), and one hit a known ID; the other source’s mix leans the other way. Time-to-resolution lands in the seconds-to-a-minute range.
A neat trick: the offline MangaBaka dump
Fuzzy matching means hitting the provider’s search endpoint a lot, and I didn’t want to hammer MangaBaka’s API (or depend on it being up) for every ambiguous release. MangaBaka publishes a full database dump, so the MangaBaka provider uses a three-layer lookup: an in-memory negative cache, then a read-only offline copy of the dump, then the live API only as a last resort (and only if you’ve opted in with a key).
The part I’m happiest with: the offline dump isn’t re-ingested into Tsundoku’s own tables. It’s opened as-is, read-only, as a side database. The refresh job streams down series.sqlite.tar.gz, validates the content of the extracted dump (rather than trusting the upstream checksum sidecar), adds a handful of source-ID indexes and an FTS5 full-text mirror over the active rows, and that’s it. Refreshes download to a temp path and atomically rename into place, so in-flight readers keep using the old store right up until the swap. No migration, no copy, no drift between “the dump” and “my copy of the dump.”
The Review Queue: Where the Machine Gives Up Gracefully
No automatic resolver is perfect, and I’d rather have a system that knows when it’s unsure than one that confidently mislabels things. Everything the pipeline couldn’t resolve, ambiguous matches, plausible-but-low-confidence guesses, format mismatches, lands in a review queue.
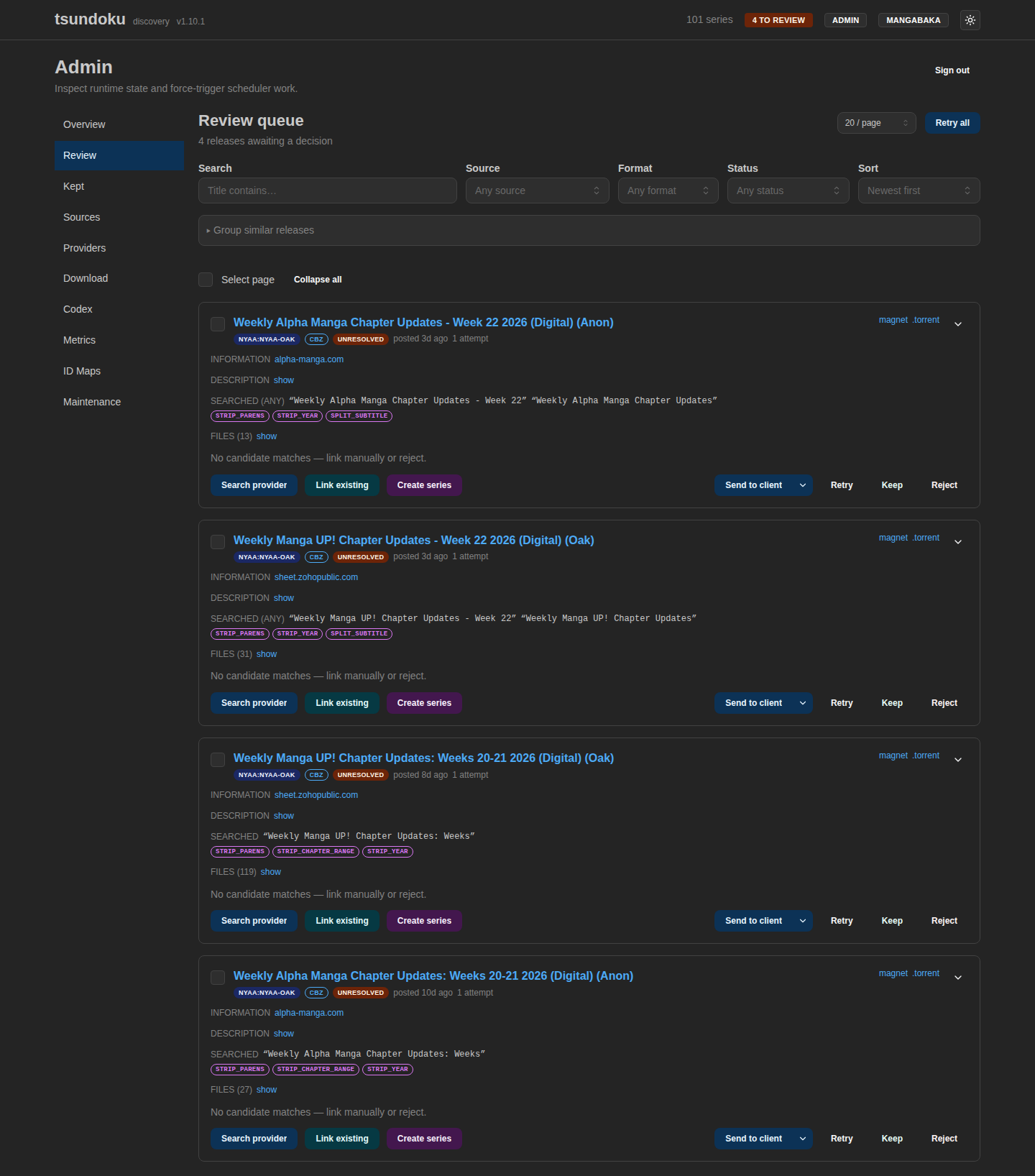
The review queue with a few releases awaiting a decision. Each row shows its extracted links, candidate matches, and the cleaned search query, with link / keep / reject / send-to-client actions inline.
The queue does a few things to keep the manual work small. Near-identical postings (the same series re-released by three groups) collapse into one row grouped by their cleaned search query, with a count and a hint at the dominant candidate. Comment-sourced links are surfaced as untrusted suggestions, never auto-resolved, because a rando in the comments is not an authoritative source. And the bulk actions let me link, reject, or “keep” many releases at once. “Keep” is for the legitimate edge cases: artbooks, guidebooks, one-shots that aren’t really a series but I still want browsable.
The honest truth is that the review queue is the feature that makes the automatic parts safe to trust. Because there’s a graceful place for “I’m not sure” to go, the confident path is allowed to be confident.
Knowing What I Already Own
This is where Tsundoku and Codex shake hands. A discovery catalog is only useful if it can tell me what’s actually new to me. So Tsundoku queries Codex’s HTTP API (read-only, over the wire, never touching its database) and overlays ownership onto every series in the feed.
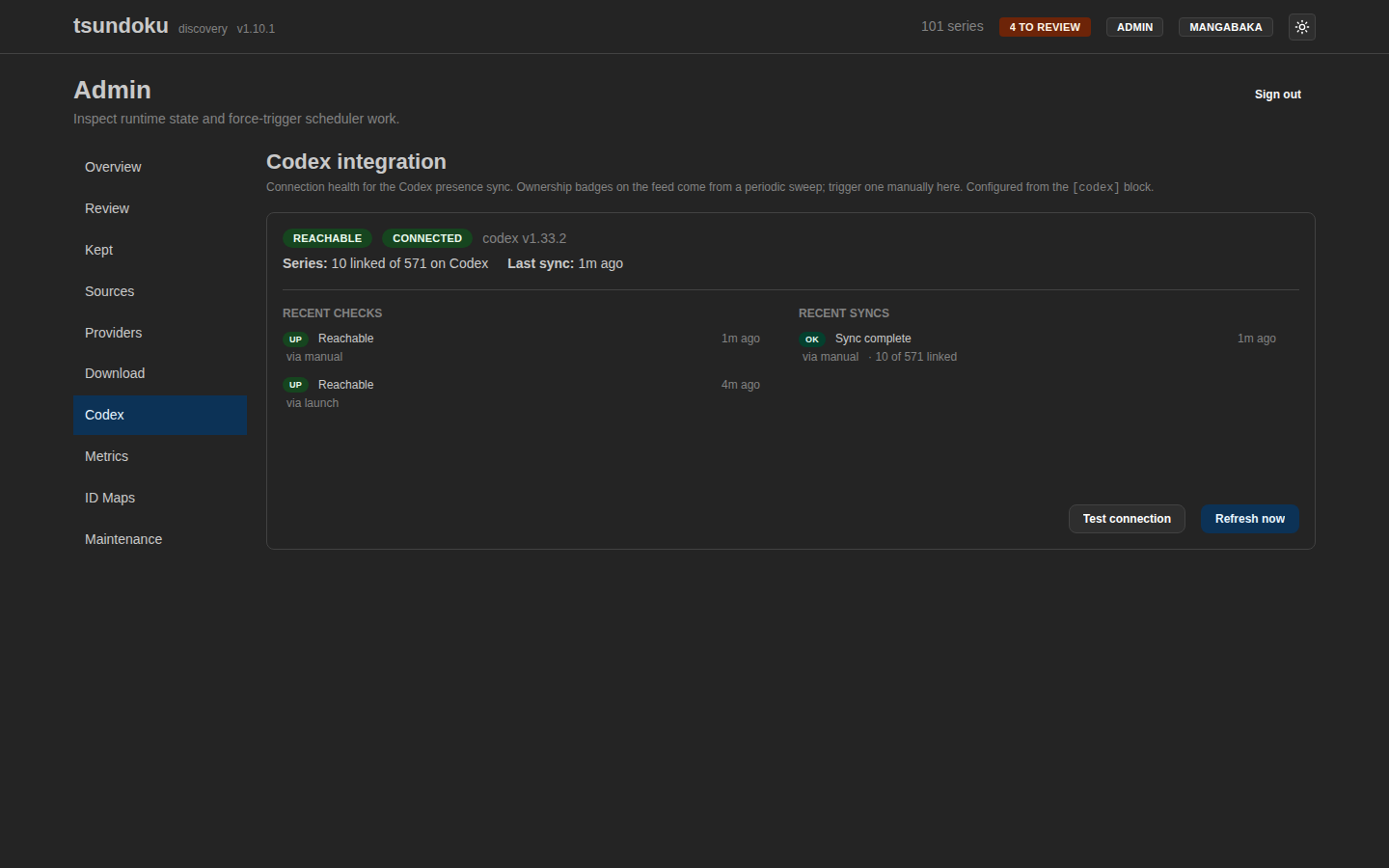
The Codex integration page: a reachability snapshot, recent connection checks, and sweep history. Ownership badges on the feed come from a periodic presence sweep.
Codex exposes an external-index endpoint that pages through every series it knows about, with their external IDs and owned volume/chapter highs. Tsundoku normalizes those provider names so they line up with its own series_external_ids, and from that it derives a presence status for each series: missing, present, complete, or behind. The behind case is the one I actually care about day to day, a series I own where new volumes exist that I don’t have yet.
There’s also an ignored status, which started as a real-world annoyance. Some series get released as omnibus editions whose volume numbering structurally runs ahead of the source, so they’d always show as “behind” no matter what. Rather than let those nag me forever, there’s a per-series opt-out flag that short-circuits the comparison. A small feature, but exactly the kind of thing you only discover you need once you’re using the tool for real.
Connection health follows a pattern I’ve come to like and reuse: a single-row snapshot of the current state, plus an append-only history table that only gets a row when reachability actually flips (or on a manual test). A health check every few minutes leaves an uptime timeline, not a million identical “still up” rows.
Closing the Loop: Send to Torrent Client
Discovery without action is just a nicer way to feel behind. So there’s one optional, admin-only button that closes the loop: send a discovered release to my torrent client.
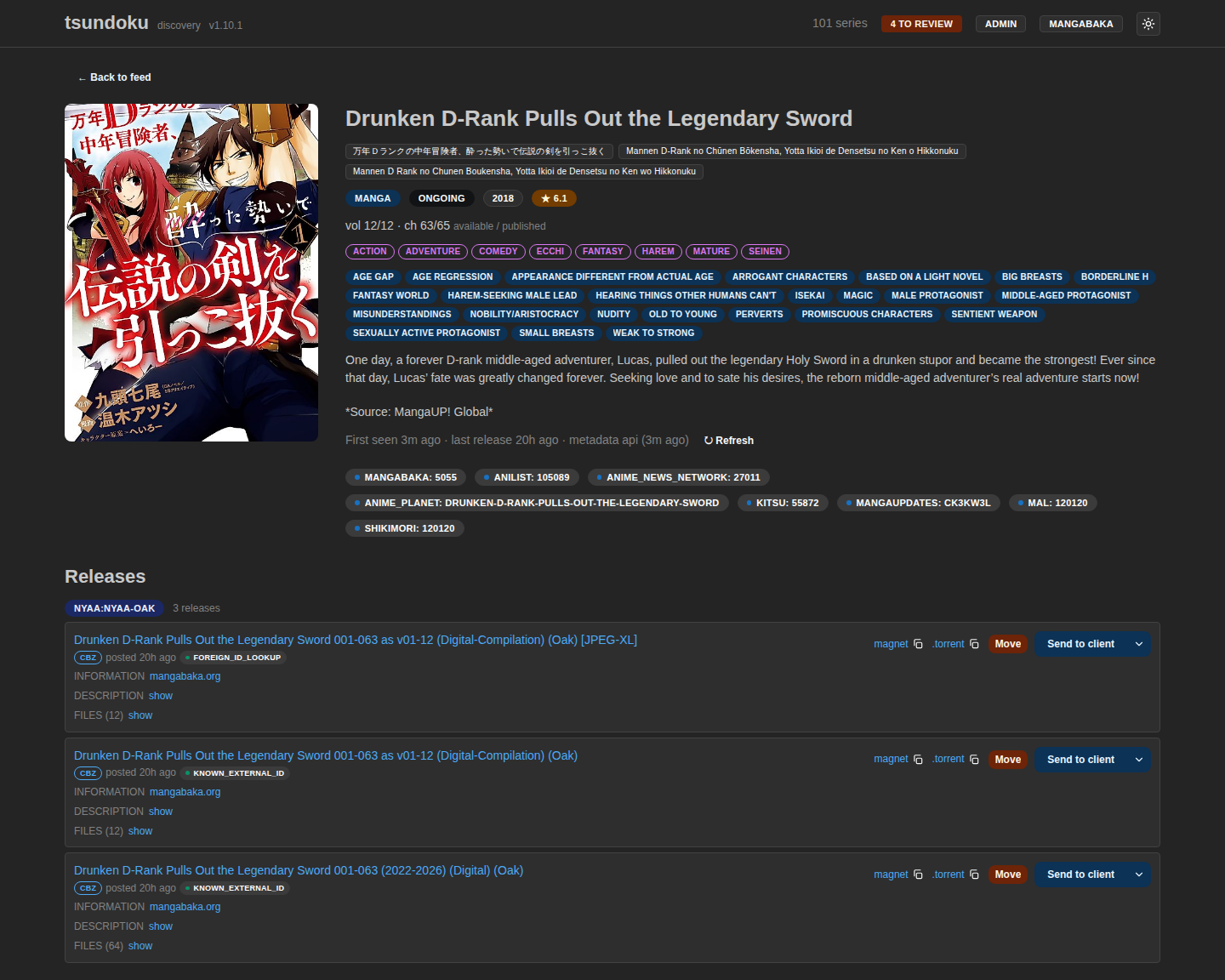
A resolved series detail page: full metadata, genres and tags, and the per-release ‘Send to client’ button that pushes a release straight to the configured torrent client.
This is deliberately the only thing Tsundoku does with torrents. It doesn’t manage them, watch them, or post-process them. It pushes the release to my client and stamps a “Sent” badge on it so I don’t double-send. It’s off by default and configured entirely from a [download] block in the config; there’s no setup UI, exactly like the Codex integration. The whole thing sits behind a DownloadClient trait with ruTorrent as the only v1 implementation.
The one genuinely annoying part deserves a war story. My seedbox’s ruTorrent sits behind Apache with Digest auth, and reqwest (the Rust HTTP client) doesn’t do Digest natively. I first tried driving ruTorrent’s web UI directly via its addtorrent.php multipart upload, and the Digest-protected Apache kept rejecting reqwest’s multipart POST with a 400. After enough head-scratching I dropped that path entirely and went to XML-RPC, the same wire protocol Prowlarr and Sonarr speak to rTorrent. That meant writing a small auth layer that tries preemptive Basic, and on a 401 Digest challenge computes the Digest response (via the digest_auth crate) and retries once. XML-RPC turned out to be the better path regardless: it’s the same load.raw_start / load.start calls the established tools use, and it leaves the door open to real download lifecycle later. The dead-end was worth it for landing on the right abstraction.
Every send, success or failure, is written to an audit table, so a failed push surfaces as a visible failed attempt instead of vanishing into a 502.
The Shape of It
Under the hood, Tsundoku is the same operational template I keep reaching for, and the reason I keep reaching for it is that it lets me spend my energy on the interesting parts (the resolution pipeline) instead of the plumbing.
- Backend: Rust (edition 2024), axum 0.8, tokio, sea-orm 1.1 over SQLite in WAL mode. The connection pool is pinned to a single connection so per-connection
PRAGMAs actually stick.utoipagenerates the OpenAPI spec, Scalar serves it at/docs. - Frontend: React 19, Vite, Mantine 9, Zustand, TanStack Query + Router. The API client is fully typed by
openapi-typescriptgenerating types from the utoipa spec, so the moment I change a Rust DTO, the TypeScript types follow. One source of truth, database to component. - Real-time: SSE, not WebSockets. The only channel so far streams manual job lifecycle events to the UI.
- Scheduler: one cron per source poll, per provider cache refresh, and so on, all guarded by a shared lock map so a manual “poll now” can’t race a scheduled tick.
- Packaging: multi-stage Docker build to a musl static binary on Alpine, a separate cross-compile Dockerfile that always runs the compiler on x86_64 (no QEMU-emulated rustc), cargo-dist for installers, git-cliff for the changelog.
It’s a workspace of focused crates (td-source, td-metadata, td-resolution, td-scheduler, td-codex, td-download, and friends), each owning one seam of the system. The crate boundaries mostly fell out of the traits.
Where It’s At
v1 is done and the project is well past it. Both of the things I’d originally filed under “maybe later”, the Codex presence integration and send-to-torrent-client, have landed, along with a pile of post-v1 quality-of-life work: standalone/kept releases, manual series with an editor, the completion-tracking opt-out, review-queue grouping and bulk actions, a cover proxy/cache, historical metrics dashboards, per-host outbound rate limiting, and persisted display preferences. Current tag is v1.10.1.
Codex told me what I own. Tsundoku tells me what I’m missing. The pile is still growing, but at least now I can see it.
The code is on GitHub, and the docs live at tsundoku.4sh.dev.