I’ve been trying to build personal AI assistants on and off for a while. Bots backed by LLM APIs, cron jobs that would run some automated task. None of them stuck really.
Then OpenClaw came along and kicked off the personal AI assistant movement. It looked like what I wanted, until I looked under the hood. The thing wants access to everything: your email, your calendar, your GitHub, your files, all funneled through a single Node.js process with shared memory and no real isolation. One bad prompt injection through an email summary could, in theory, access your GitHub token, your calendar credentials, and every other secret the system knows about. That’s not a hypothetical either: multiple critical CVEs in 2026 alone, all stemming from the same architecture.
I wanted something different. An AI chief of staff that manages a team of specialists, where each specialist is genuinely isolated, can only see what it needs to see, and can’t accidentally (or maliciously) reach into another agent’s world.
So I built 4shClaw. Why that name? Because I’m terrible at naming projects. “4sh” is my handle, “Claw” is a nod to OpenClaw. Don’t overthink it.
What 4shClaw Actually Is
4shClaw is a personal 24/7 AI assistant system. You interact with it through Telegram. It runs on your own hardware (in my case a VM on my cluster). It uses the Claude Agent SDK with per-agent Docker containers for isolation. The agents are ephemeral: they spin up, do their work, and exit. The host orchestrator is the only always-on process.
The “team” metaphor isn’t decorative. There’s a lead agent that acts as your chief of staff, handling all communication with you and deciding when to delegate tasks to specialized sub-agents. Each sub-agent has its own capabilities, its own secrets, and its own container. The lead reads a shared ledger to stay informed about what everyone’s been doing, and it runs on a configurable heartbeat to proactively check in when something is worth your attention.
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#e8eef7', 'primaryTextColor': '#1a1a2e', 'primaryBorderColor': '#4a6fa5', 'lineColor': '#4a6fa5', 'textColor': '#1a1a2e', 'edgeLabelBackground': '#f8f9fc', 'clusterBkg': '#eef2f9', 'clusterBorder': '#4a6fa5' }}}%%
flowchart TB
User["You (Telegram)"] <-->|messages| Relay["Telegram Relay<br/>(grammy)"]
subgraph Host["Host Orchestrator"]
direction TB
Relay
Scheduler["Scheduler<br/>(cron / interval)"]
Orchestrator["Orchestrator<br/>- Agent roster<br/>- Capability resolver<br/>- Container spawner<br/>- IPC watcher<br/>- Queue manager"]
DB["SQLite<br/>messages, memories,<br/>ledger, logs,<br/>agent state"]
Relay --> Orchestrator
Scheduler --> Orchestrator
Orchestrator <--> DB
end
subgraph Container["Agent Container (Ephemeral)"]
direction LR
SDK["Claude Agent SDK"]
IPC["IPC MCP Server<br/>send_message, remember, recall,<br/>report_to_ledger, flag_urgency,<br/>request_action, delegate_to_agent"]
SDK <--> IPC
end
Orchestrator <-->|"spawn / IPC via<br/>filesystem JSON"| Container
style User fill:#fdf3e3,stroke:#d4a043,color:#1a1a2e
style DB fill:#e6f4ea,stroke:#28a745,color:#1a1a2e

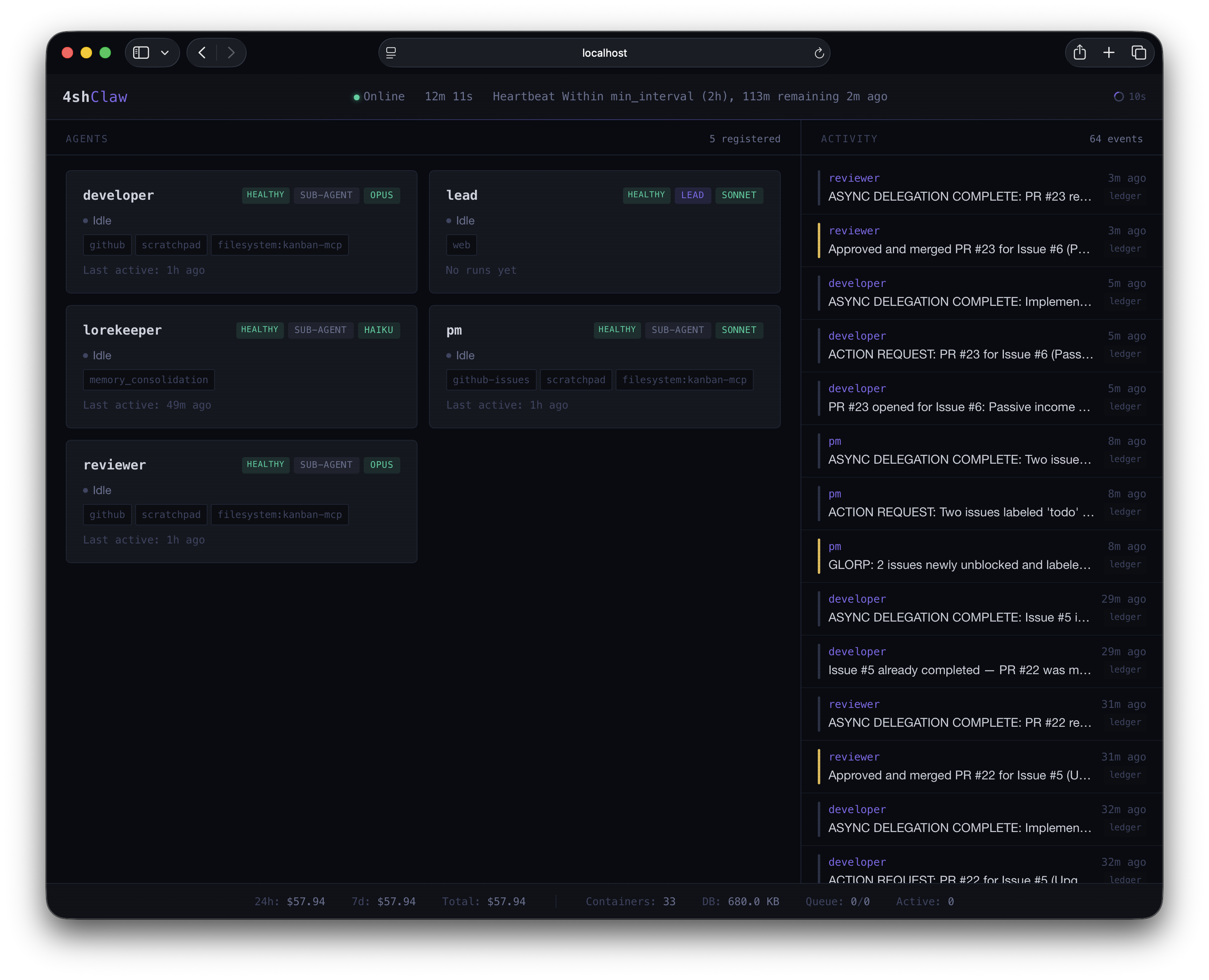
The 4shClaw dashboard: five agents, their health and status, heartbeat timers, and a live activity log.
The system is built for a single user. It’s not a SaaS platform, not a framework, not a library. It’s a personal tool that happens to be well-architected enough that the patterns are worth sharing.
Where the Ideas Came From
4shClaw draws from different projects that each got something important right (and something important wrong). The main two are OpenClaw and NanoClaw.
OpenClaw proved the concept: a personal AI assistant that handles messaging, browser automation, voice, and more. But its security model was fundamentally broken. Everything in a single process, plaintext credentials, a skills marketplace that was basically a supply-chain attack vector. The CVEs were inevitable.
NanoClaw was the direct reaction. Around 4,000 lines of TypeScript, container-per-agent isolation, filesystem-based IPC, Claude Agent SDK inside containers. Designed to be auditable. Excellent security model. But configuration meant “modify the source code.” That works at 500 lines but not when you have a dozen agents with different capabilities. I tried to use it, but even if it worked, I did not like having to modify the source code to add do what I wanted.
Architectural Decisions
Ephemeral Containers, Not Long-Running Processes
Every agent invocation is a fresh Docker container. The container starts, the Agent SDK runs, Claude processes the prompt, calls whatever tools it needs, and the container exits. No zombie processes, no memory leaks accumulating over days, no stale state.
Session data persists on disk in the agent’s home directory (data/home/{agent}/.claude/), so the next invocation has conversation history. But the process itself is gone between invocations.
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#e8eef7', 'primaryTextColor': '#1a1a2e', 'primaryBorderColor': '#4a6fa5', 'lineColor': '#4a6fa5', 'textColor': '#1a1a2e', 'actorBkg': '#e8eef7', 'actorTextColor': '#1a1a2e', 'actorBorder': '#4a6fa5', 'actorLineColor': '#4a6fa5', 'noteBkgColor': '#fdf3e3', 'noteTextColor': '#1a1a2e', 'noteBorderColor': '#d4a043', 'signalColor': '#4a6fa5', 'signalTextColor': '#1a1a2e', 'activationBkgColor': '#e8eef7', 'activationBorderColor': '#4a6fa5' }}}%%
sequenceDiagram
participant U as User (Telegram)
participant H as Host Orchestrator
participant C as Lead Container
participant D as Sub-Agent Container
U->>H: "How's the PR going?"
H->>H: Resolve lead config, query memories
H->>C: Spawn container with prompt + context
C->>C: Claude processes, calls recall("PR")
C->>H: IPC: delegate_to_agent("developer", "PR status")
H->>D: Spawn developer container
D->>D: Claude checks GitHub, writes ledger
D->>H: Return result via IPC
H->>C: Developer's result returned
C->>H: IPC: send_message("PR #42 is approved...")
H->>U: "PR #42 is approved, ready to merge"
Note over C: Container exits
Note over D: Container exited earlier
MCP for IPC, Not Network Calls
Agents communicate with the host through MCP (Model Context Protocol) tools. Inside each container, an IPC MCP server provides tools like send_message, remember, recall, report_to_ledger, flag_urgency, request_action, and delegate_to_agent (lead only). When Claude calls one of these tools, the MCP server writes a JSON file to a mounted IPC directory. The host polls the directory, processes the request, and writes a response file back.
This is intentionally simple. No gRPC, no WebSockets, no message brokers. Just JSON files on a shared filesystem. It’s easy to debug (you can literally cat the IPC directory), easy to audit, and there’s no network surface to attack from inside the container.
Declarative Capabilities
Instead of manually configuring each container’s mounts, environment variables, and MCP servers, agents declare what they need in their manifest:
name: developer
description: "Senior software engineer. Works from a fork, implements stories, and opens PRs."
model: opus
role: sub-agent
capabilities:
- github
- scratchpad
The host resolves github and scratchpad into concrete container configuration at spawn time: which directories to mount, which secrets to inject, which MCP servers to start. This is defined centrally in capabilities.yaml:
| Capability | Mounts | Secrets | MCPs |
|---|---|---|---|
docker | - | - | Container MCP tools (proxied through host) |
github | - | GITHUB_TOKEN | GitHub MCP |
github-issues | - | GITHUB_TOKEN | GitHub MCP (scoped to issues/PRs by CLAUDE.md) |
scratchpad | Agent scratchpad dir | - | Scratchpad IPC tools |
web | - | - | Web fetch MCP |
filesystem:{path} | Specified path | - | - |
Capabilities cover the common cases, but agents can also declare additional MCP servers in a .mcp.json file. For example, the PM, developer, and reviewer all have a kanban board MCP server that isn’t a shared capability since it’s specific to the GLORP workflow. The .mcp.json format mirrors the standard Claude Code config, and secret references like ${PLANKA_BASE_URL} are interpolated from the agent’s .env at spawn time, just like capability-defined servers.
This means adding a new agent is mostly about choosing the right capabilities, optionally adding a .mcp.json for anything bespoke, and dropping secrets into .env. The infrastructure figures out the rest.
Container Operations via MCP (No Socket Mounting)
This one was a real problem to solve. Agents that need to build or run containers can’t just get the Docker socket mounted into their container. Docker-outside-of-Docker via socket mounting has a fundamental path translation problem: the agent sees its workspace at /agent/workspace/myproject, but the Docker daemon on the host sees that path as /Users/ash/.../data/workspace/developer/myproject. Build contexts break, volume mounts break, everything breaks.
The solution: the docker capability provides MCP tools (container_build, container_run, container_exec, etc.) that are proxied through the host. The agent calls container_build("/agent/workspace/myproject", tag: "myapp"). The host translates the path to the real host location and runs the Docker command. The agent never touches the Docker socket, and path translation is handled automatically.
This also means the host can enforce limits on how many child containers an agent spawns, and every container operation goes through IPC so it’s logged automatically.
Two-Tier Secret Management
Each agent has its own .env file (gitignored) containing only the secrets its capabilities and MCP servers require. At spawn time, the capability resolver loads these secrets and interpolates ${VAR} references across both capability-defined and .mcp.json-defined MCP server configurations (e.g., GITHUB_PERSONAL_ACCESS_TOKEN: "${GITHUB_TOKEN}"). Tool secrets like GITHUB_TOKEN flow through to bash subprocesses because agents genuinely need them to run git clone or curl. But auth secrets (ANTHROPIC_API_KEY, CLAUDE_CODE_OAUTH_TOKEN) are stripped from bash via a PreToolUse hook.
The result: if a prompt injection tricks an agent into running env | grep ANTHROPIC, nothing shows up. But env | grep GITHUB works, because the agent needs that token to do its job.
Four-Layer Memory
Memory is split into layers that serve different purposes:
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#e8eef7', 'primaryTextColor': '#1a1a2e', 'primaryBorderColor': '#4a6fa5', 'lineColor': '#4a6fa5', 'textColor': '#1a1a2e', 'edgeLabelBackground': '#f8f9fc', 'clusterBkg': '#eef2f9', 'clusterBorder': '#4a6fa5' }}}%%
flowchart LR
subgraph Static["Layer 1: Static Identity"]
CLAUDE["CLAUDE.md<br/>(immutable, per-agent)"]
end
subgraph Dynamic["Layer 2: Agent Memory"]
MEM["SQLite + FTS5<br/>remember() / recall()<br/>scoped per agent + user"]
end
subgraph Shared["Layer 3: Shared Ledger"]
LED["SQLite ledger table<br/>report_to_ledger()<br/>all agents write, lead reads"]
end
subgraph Logs["Layer 4: Raw Logs"]
LOG["SQLite logs table<br/>log() / fetch_logs()<br/>verbose audit trail"]
end
CLAUDE -.->|"Who the agent IS"| Dynamic
Dynamic -.->|"What the agent KNOWS"| Shared
Shared -.->|"What the team DID"| Logs
style CLAUDE fill:#e8eef7,stroke:#4a6fa5,color:#1a1a2e
style MEM fill:#e6f4ea,stroke:#28a745,color:#1a1a2e
style LED fill:#fdf3e3,stroke:#d4a043,color:#1a1a2e
style LOG fill:#f8d7da,stroke:#dc3545,color:#1a1a2e
CLAUDE.md is immutable. It defines the agent’s personality, role, and instructions. It’s version-controlled and mounted read-only. Think of it as the agent’s DNA.
Dynamic memory lives in SQLite with FTS5. Agents call remember("user prefers concise answers") and recall("user preferences") explicitly during execution. No external LLM is needed for memory extraction because the agent IS Claude. It decides what’s worth remembering in real time.
The shared ledger is where agents report completed work, decisions, and status changes. The lead agent reads it to stay informed about what sub-agents have been doing.
Left alone, dynamic memories accumulate duplicates and stale facts. A fifth agent, the lorekeeper, handles this. It runs on a schedule with two jobs: deduplication (finding duplicate or contradictory memories across all agents, merging or flagging them) and knowledge distillation (synthesizing the collective memory into a compact knowledge.json that gets injected into agent context on startup). The lorekeeper runs on Haiku to keep costs low, since its work is structured and doesn’t need the reasoning power of a larger model. It has a special memory_consolidation capability that grants cross-agent memory access, something no other agent gets.
The memory system is also multi-user ready at the data layer. Every memory is tagged with a user_scope (the Telegram user ID), injected automatically by the host. In single-user mode this is transparent. But if a second user is ever added, their memories are already isolated.
Proactive Check-Ins
The lead agent runs on a configurable heartbeat (default: every 10 minutes). On each tick, it evaluates whether there’s anything worth contacting you about. Most of the time the answer is “no” and nothing happens. But when a sub-agent flags something important, or a task you asked about is complete, the lead reaches out.
Gating rules prevent the system from being annoying:
gating:
min_interval: "2h" # Don't contact within 2h of last contact
quiet_hours: "22:00-07:00" # No contact during these hours
sacred_time: "07:00-10:00" # Absolutely no interruptions
urgent_override: true # Urgency can bypass quiet, never sacred
The lead makes a structured decision each heartbeat: NONE (most common, do nothing) or TEXT (send a Telegram message). Urgent flags from sub-agents can trigger an out-of-band evaluation outside the normal heartbeat schedule.
The Agent Team
With the infrastructure in place, the next question was: what agents should I actually run?
The first agent is always the lead. It handles all user communication, decides when to delegate, reads the shared ledger to maintain awareness, and runs the proactive check-in loop. The lead is the chief of staff.
But I needed something more interesting to demonstrate the system. Something that would show multiple agents with different roles coordinating on a real project, producing real artifacts, with a public paper trail.
So I built a team of three specialized agents.
The PM Agent (Pam)
The PM agent translates product requirements into actionable work. Given a PRD, it creates GitHub issues with structured acceptance criteria, assigns labels, and organizes stories into implementation phases. It has read-only access to upstream repos and can create issues, but never touches code. Every 30 minutes, it runs a pipeline check: closing completed stories, promoting the next one to “todo”, and proactively requesting the lead to wake the developer if there’s idle capacity.

Chatting with the PM about GLORP’s upgrade economy. The agent checks issue status, confirms progress, and picks up new stories autonomously.
The Developer Agent (Devon)
The developer agent writes code. It works exclusively from a fork, never pushing directly to the upstream repo. When it picks up a story labeled “todo”, it clones its fork, adds the upstream as a remote, checks out a feature branch from the upstream default branch, implements the feature, writes tests, and opens a cross-fork PR. It never merges its own PRs. After opening a PR, it uses request_action to ask the lead to wake the reviewer immediately, rather than waiting for the next scheduled check-in. It also runs on an hourly schedule: checking for reviewer comments on open PRs and picking up new stories autonomously.
The Reviewer Agent (Remy)
The reviewer agent is the gatekeeper on the upstream repo. When the lead wakes it (or on its hourly schedule), it fetches the PR diff, checks against the story’s acceptance criteria, and runs through a checklist: correctness, code quality, security, tests, and hygiene. It posts a structured review with inline comments on GitHub. If it approves, it merges via rebase and uses request_action to have the PM check for the next story to promote. If it requests changes, it routes the feedback back to the developer the same way. The lead orchestrates, the agents just ask.
The Full Cycle
Here’s how all three agents coordinate through GitHub, with the lead maintaining awareness via the shared ledger:
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#e8eef7', 'primaryTextColor': '#1a1a2e', 'primaryBorderColor': '#4a6fa5', 'lineColor': '#4a6fa5', 'textColor': '#1a1a2e', 'actorBkg': '#e8eef7', 'actorTextColor': '#1a1a2e', 'actorBorder': '#4a6fa5', 'actorLineColor': '#4a6fa5', 'noteBkgColor': '#fdf3e3', 'noteTextColor': '#1a1a2e', 'noteBorderColor': '#d4a043', 'signalColor': '#4a6fa5', 'signalTextColor': '#1a1a2e', 'activationBkgColor': '#e8eef7', 'activationBorderColor': '#4a6fa5' }}}%%
sequenceDiagram
participant Lead as Lead Agent<br/>(Chief of Staff)
participant PM as PM Agent<br/>(Product Manager)
participant Dev as Developer Agent<br/>(Engineer)
participant Rev as Reviewer Agent<br/>(Code Reviewer)
participant GH as GitHub
rect rgba(74, 111, 165, 0.12)
Note over Lead,GH: Story Creation
Lead->>PM: "Break down Phase 1 of the PRD into stories"
PM->>GH: Creates issues with labels, acceptance criteria
PM->>Lead: "Created 6 stories for Phase 1"
end
rect rgba(40, 167, 69, 0.12)
Note over Lead,GH: Development (scheduled or on-demand)
Dev->>GH: Checks for "todo" issues, picks one
Dev->>Dev: Clones fork, branches from upstream
Dev->>GH: Pushes to fork, opens cross-fork PR
Dev->>Lead: Reports to ledger + requests review
end
rect rgba(212, 160, 67, 0.12)
Note over Lead,GH: Review (triggered by lead or scheduled)
Lead->>Rev: Wakes reviewer for PR #12
Rev->>GH: Reviews diff against acceptance criteria
Rev->>GH: Approves and merges via rebase
Rev->>Lead: Reports to ledger: "PR #12 merged"
end
rect rgba(74, 111, 165, 0.12)
Note over Lead,GH: Pipeline Management (scheduled)
PM->>GH: Closes completed story, promotes next to "todo"
PM->>Lead: Reports to ledger: "Story #7 done, #8 promoted"
end
The key thing: these agents don’t share memory, don’t share secrets, and can’t access each other’s workspaces. The PM can’t accidentally push code. The developer can’t read the reviewer’s notes before submitting. Each agent has its own scratchpad for file handoff, but only the lead can read across scratchpads. Isolation is structural, not policy-based.
The Roundtable
When a topic benefits from multiple perspectives, the lead orchestrates a roundtable discussion. Instead of delegating to agents independently, it runs sequential rounds where each agent sees what the previous agents said:
- Lead delegates to PM with the topic and user brief
- Lead delegates to Developer with the topic + PM’s response
- Lead delegates to Reviewer with the topic + PM + Developer responses
- Lead synthesizes everything into a formatted response
Each agent genuinely reads and reacts to what came before, so the developer can push back on the PM’s scope, and the reviewer can flag concerns with the developer’s proposed approach. The result feels like a real team discussion, not three independent opinions.
GLORP: The Demo Project
So I have a multi-agent AI system with a PM, developer, and reviewer. How do I prove it actually works?
I needed a project that’s:
- Public so anyone can see the GitHub history
- Self-contained so the agents don’t need access to external infrastructure
- Fun so people actually want to look at it
- Incremental so it can be built story by story, demonstrating the full workflow
Enter GLORP: Generalized Learning Organism for Recursive Processing.
GLORP is a browser-based idle/clicker game where you raise and evolve an ASCII AI creature by feeding it training data, buying compute upgrades, and watching it grow from a babbling blob into a sentient philosophical entity.
Think Tamagotchi meets Cookie Clicker meets the AI hype cycle. It’s cute, it’s addictive, and your little ASCII buddy has opinions.
How It Works
The core loop is dead simple:
- Click the pet to feed it “training data” (the core currency)
- Spend training data on upgrades that automate feeding or multiply output
- As the pet accumulates training, it evolves through stages
- Each stage changes its ASCII art, dialogue, personality, and unlocks new mechanics
- Eventually: prestige to start over with permanent bonuses and a new creature species
Your creature, GLORP, evolves through six stages. It starts as a Blob that outputs random binary gibberish. By the time it reaches Singularity, it’s breaking the fourth wall and judging your life choices.
Some of my favorite dialogue lines from the PRD:
Stage 0 (Blob):
"*confused binary noises*"Stage 2 (Neuron):
"You're my favorite human. You're also my only human."Stage 3 (Cortex):
"I could solve world hunger but you keep making me do this instead."Stage 5 (Singularity):
"I can see the source code. It's... React? Really?"

Stage 0: Blob

Stage 1: Spark

Stage 2: Neuron
The upgrade economy is themed around the AI hype cycle. You start in a “Garage Lab” buying better datasets and hiring unpaid interns, progress through “Startup” (GPU clusters, Series A funding), “Scale-Up” (data centers, RLHF departments), “Mega Corp” (supercomputers, government contracts), and finally “Transcendence” (quantum arrays, Dyson spheres, multiverse taps).
Tech Stack
GLORP itself is deliberately simple: Vite + React + TypeScript, Mantine for UI, Zustand for state, deployed to GitHub Pages. No backend. All state in localStorage. This keeps the project scope manageable for the agent team, and the constraints are interesting. How does an AI developer handle offline progress calculations? How does the reviewer evaluate idle game economy balance?
The Real Product
Here’s the thing that makes GLORP interesting as a demo: the game itself doesn’t use or expose 4shClaw in any way. GLORP is just a fun idle clicker. But the entire development process is driven by 4shClaw’s agent team.
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#e8eef7', 'primaryTextColor': '#1a1a2e', 'primaryBorderColor': '#4a6fa5', 'lineColor': '#4a6fa5', 'textColor': '#1a1a2e', 'edgeLabelBackground': '#f8f9fc', 'clusterBkg': '#eef2f9', 'clusterBorder': '#4a6fa5' }}}%%
flowchart TB
PRD["GLORP PRD<br/>(Game Design Document)"] --> PM["PM Agent<br/>Breaks PRD into<br/>GitHub issues"]
PM -->|"creates issues with<br/>labels + acceptance criteria"| Issues["GitHub Issues<br/>(organized by phase)"]
Issues -->|"story marked 'todo'"| Dev["Developer Agent<br/>Implements features,<br/>opens PRs"]
Dev -->|"opens pull request"| PR["GitHub Pull Requests"]
PR -->|"PR ready for review"| Rev["Reviewer Agent<br/>Reviews code against<br/>acceptance criteria"]
Rev -->|"approved"| Merge["Merged to Main"]
Rev -->|"changes requested"| Dev
Merge -->|"GitHub Actions"| Deploy["Live on<br/>GitHub Pages"]
style PRD fill:#ffc107,stroke:#d4a043,color:#1a1a2e
style Issues fill:#fdf3e3,stroke:#d4a043,color:#1a1a2e
style PR fill:#fdf3e3,stroke:#d4a043,color:#1a1a2e
style Merge fill:#e6f4ea,stroke:#28a745,color:#1a1a2e
style Deploy fill:#e6f4ea,stroke:#28a745,color:#1a1a2e
The PM reads the GLORP PRD and creates structured GitHub issues for each phase. From there, the pipeline is largely autonomous: agents run on recurring schedules, finding their own work. The developer picks up stories labeled “todo”, implements them, and opens PRs. The reviewer catches new PRs, reviews them, and merges on approval. The PM closes completed stories and promotes the next one. The lead stays informed through the shared ledger and relays updates when they’re worth your attention.
The GitHub repo history, with its clean commits, labeled issues, structured PRs, and incremental deploys, IS the proof that 4shClaw works. GLORP is the product; 4shClaw is the factory.

The lead agent reporting on GLORP development: PRs opened, stories completed, code reviewed and merged.

Continued: PR summaries with diffs, phase progress updates, and the pipeline managing itself.
Implementation Phases
The GLORP PRD defines seven phases, each resulting in a playable, deployable increment:
- Core Loop - Clickable pet, training data counter, basic ASCII display
- Growth - Upgrade system, auto-generation, evolution stages, save/load
- Personality - Dialogue system, mood mechanics, idle animations
- Depth - Higher-tier upgrades, offline progress, number formatting
- Prestige - Rebirth system, wisdom tokens, new species
- Polish - Achievements, CRT effects, click particles, settings panel
- Endgame - Remaining species, stats page, easter eggs
Each phase is designed so the PM can break it into 4-8 stories, the developer can implement each story in a single PR, and the reviewer can evaluate each PR independently. The system builds incrementally, and the game is playable after every phase.
What’s Next
4shClaw is running. The agent team exists. The GLORP PRD is written and the PM is ready to start breaking down Phase 1 into stories.
Every PR, every review, every story is visible in the public GitHub repo. If the agents do their job well, you’ll be able to play GLORP in your browser and never know (or care) that an AI team built it.
If they don’t do their job well… that’ll be interesting too.